
AI en gegevenswetenschap updates
22 aug 2025
Samen Bouwen: Arindam's Reis in het Bevorderen van Open-Source Conversatie Intelligentie
Na zeven maanden toegewijd werk bij Dembrane, gaat Arindam verder met het nastreven van zijn eigen agentisch grafproject. Zijn bijdragen hebben ons geholpen enkele van de moeilijkste uitdagingen aan te pakken om conversatie-intelligentie toegankelijk en praktisch te maken voor gemeenschappen overal ter wereld. Terwijl hij overgaat naar zijn volgende avontuur, wilden we de technische reis delen die we samen hebben doorgemaakt om de open-source bijdragen te documenteren die anderen met vergelijkbare uitdagingen kunnen helpen.

Productieklaar kennisgrafieken
Toen we voor het eerst Microsoft's GraphRAG tegenkwamen, waren we enthousiast over de belofte: verbanden tussen ideeën begrijpen op manieren die traditionele RAG niet konden. Maar we stuitten al snel op een muur waar veel startups tegenaan lopen — de academische implementatie was niet klaar voor de rommelige realiteit van doorlopende gemeenschapsconversaties.
Het probleem was eenvoudig maar verwoestend: elke keer dat je nieuwe gesprekken aan de grafiek wilde toevoegen, moest je de grafiek helemaal opnieuw opbouwen.
Via een vriend van het bedrijf werden we in de richting van LightRAG van de Universiteit van Hong Kong gewezen. Nu konden we in plaats van dagelijks grafieken opnieuw op te bouwen tegen onhoudbare kosten, ze incrementeel bijwerken naarmate nieuwe gesprekken binnenkomen.
Het was efficiënter, maar het voldeed nog steeds niet helemaal aan onze behoeften. In samenwerking met de open-source gemeenschap hielp Arindam met het toevoegen van metadata-ondersteuning die de context van de gesprekken behoudt zonder de grafiekstructuur te compromitteren, waardoor we LightRAG in productie konden gebruiken. We hebben deze verbeteringen terug bijgedragen aan het LightRAG-project.
Luisteren op schaal met BERTopic
Onze kernuitdaging is het helpen van gemeenschappen om zichzelf te begrijpen. Wanneer je honderden uren aan gesprekken hebt, hoe breng je dan de thema's naar voren die ertoe doen zonder de nuances te verliezen? Simpelweg alle context toevoegen aan een AI-prompt kan goed werken voor kleine focusgroepen, maar faalt catastrofaal als je schaalt naar stadsbrede consultaties.
Het implementeren van RAG helpt, maar het heeft een kritieke tekortkoming: wanneer je een traditioneel RAG-systeem vraagt om de "inhoud samen te vatten" van een grote dataset - Het zoekt naar inhoud die lijkt op de query "inhoud samen te vatten." Omdat er geen inhoud is die lijkt op de query "inhoud samen te vatten," geeft het systeem een hoop ogenschijnlijk willekeurige context die een ondermaats resultaat oplevert.
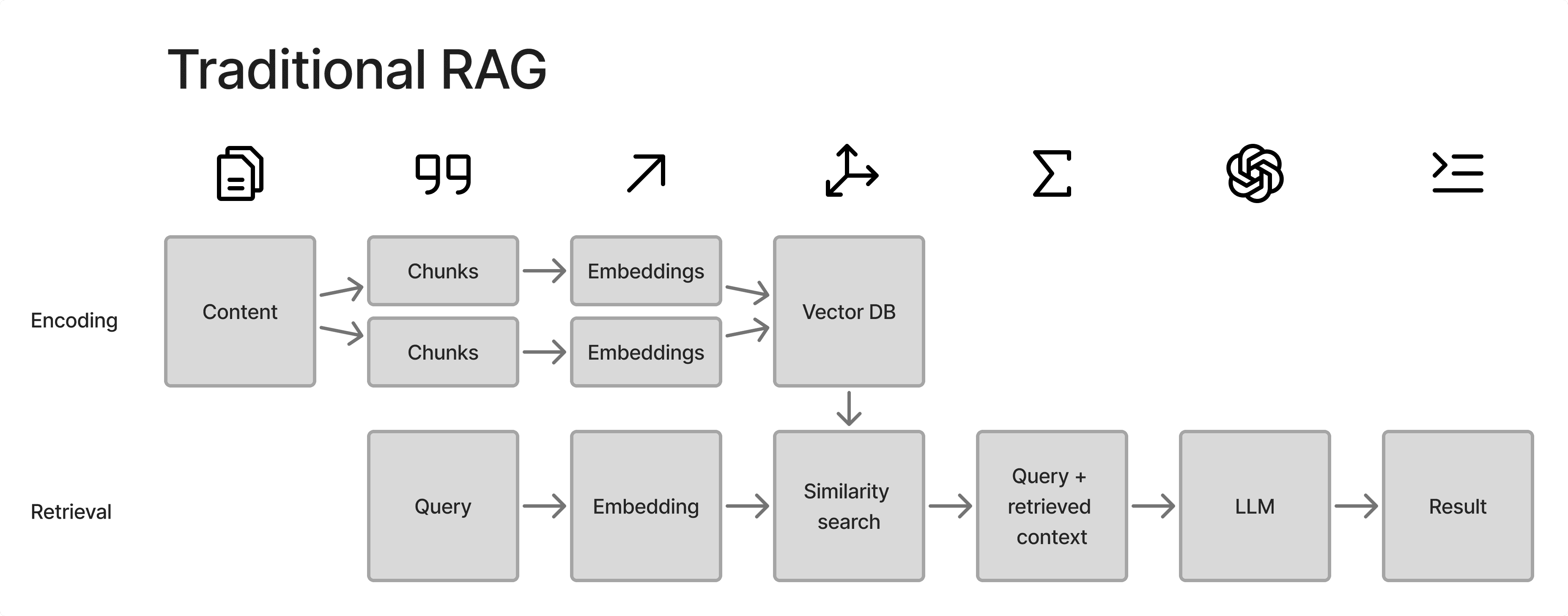
Arindam kwam op het briljante idee om een traditionele machine learning techniek (BERTopic) te implementeren om deze beperking te overwinnen.
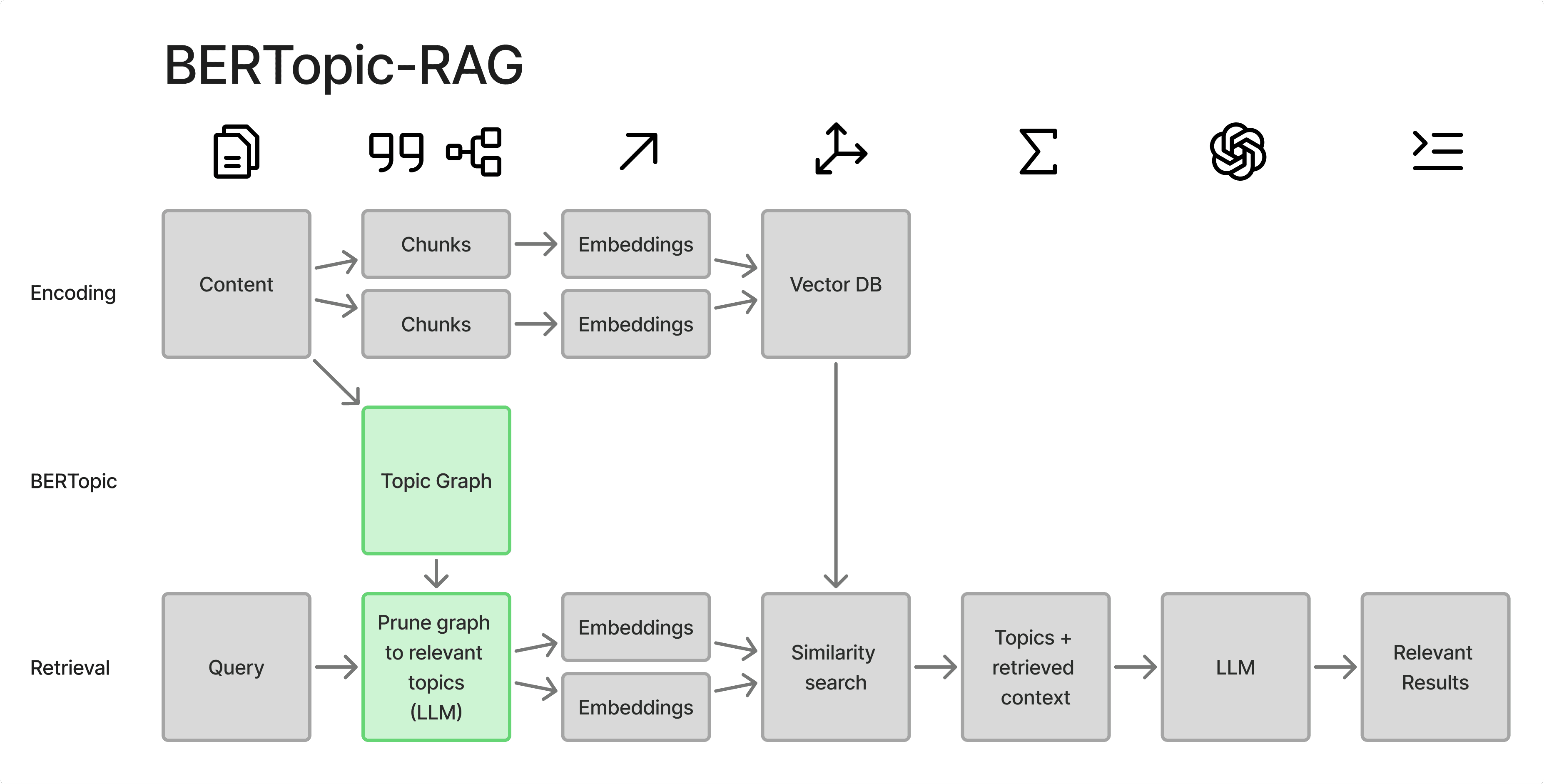
In plaats van simpelweg te zoeken naar inhoud die lijkt op de query, creëert BERTopic hiërarchische onderwerpstructuren waarbij thema's verstrengeld zijn binnen bredere concepten. Dit stelt een LLM in staat om van algemene ideeën naar specifieke discussies te navigeren, net als in- en uitzoomen op een kaart.
De magie gebeurt wanneer iemand vraagt: "Wat zeggen PEOPLE KNOW HOW over de nieuwe fietspaden?" Het systeem doorzoekt niet miljoenen gesprekstukken om de meest relevante stukken te vinden (die misschien stukken zijn waarin mensen letterlijk vragen over fietspaden). In plaats daarvan doorloopt het de onderwerpstructuur, waarbij het relevante takken identificeert (vervoerszorgen, veiligheidsfeedback, milieuvoordelen, fietspaden), en vervolgens alle relevante context aan de LLM geeft bij het beantwoorden van de vraag.
Dit is specifiek nuttig bij het beantwoorden van de soorten vragen die opkomen wanneer je probeert brede zorgen te begrijpen in grote sets gesprekken die veel specifieke onderwerpen raken. Samenwerkend met onze CTO Sameer, hebben we deze methode in productie gebracht en we delen graag deze nieuwe techniek met de wereld!
Meertalige fijnstelling
Werken met Europese gemeenten heeft ons geleerd dat privacy niet optioneel is. Spraakopnamen bevatten biometrische gegevens, waardoor ze persoonlijk identificeerbaar zijn onder de AVG. We konden geen cloud-transcriptiediensten gebruiken die deze gegevens buiten de EU konden opslaan of verwerken. We stuitten op veel problemen om dit te laten werken, aangezien al het werk lijkt te gaan naar het optimaliseren van Engelse transcriptie op gebruiksvriendelijke maar privacy-schendende API's.
Daarom experimenteerden we met het bouwen van ons eigen systeem bovenop het open-source transcriptiemodel Whisper, dat we zelf hosten. Whisper is getraind op 90+ talen maar kiest vaak voor Engels, de hoofdtaal in zijn trainingsset. Arindam bouwde pipelines om het voor ons relatief eenvoudig te maken om eigen Whisper-modellen op verschillende talen fijn af te stemmen. Het systeem stelt de gewichten van het model af op nieuwe talen op aanvraag, waarbij lokale terminologie en accenten worden geleerd zonder zijn brede capaciteiten te compromitteren. We hebben ook veel van de optimalisaties uit onderzoek in deze stack opgenomen. Waar standaard Whisper 40 minuten nodig heeft om een uur audio te verwerken, doet onze implementatie dit in ongeveer een minuut (afhankelijk van de beschikbaarheid van de GPU) — waardoor real-time gemeenschappelijke sessies mogelijk worden.
Voorlopig zijn we begonnen met het fijnstellen van Whisper voor Nederlands, maar we kijken ernaar uit om veilige, nauwkeurige en meertalige transcriptie in productie voor alle Europese talen te verbeteren, en daarna de rest van de wereld.
Speaker Diarisation
Het speaker diarisation project verdient ook speciale vermelding. We moesten bijhouden wie wat zei binnen een sessie (voor samenhangende transcripties), maar we hebben slechts één audiotrack per gesprek, in tegenstelling tot video-oplossingen die sprekers vanaf de audio-bron kunnen splitsen. Arindam implementeerde een prototypesysteem dat ons in staat stelt om de meerdere transcripties samenhangend in aparte sprekers te splitsen, zonder dat sprekers expliciet identificeerbaar worden, wat cruciaal is voor de Chatham House richtlijnen en GDPR.
Alles Samenbrengen
De echte innovatie is niet één enkel component — het is hoe ze samenwerken. Wanneer iemand vraagt: "Hoe verhouden technische zorgen zich tot klantfeedback?", begrijpt het systeem het thematische landschap via BERTopic, navigeert het door entiteitsrelaties via LightRAG, scheidt het sprekers zonder de privacy te schenden, in elke taal.
Deze synthese stelt ons in staat om stappen te nemen naar onze droom: grootschalige gemeenschapsdialoog tot een gemeengoed maken. Gemeenteraden kunnen de stemmen van duizenden burgers begrijpen. Bedrijven kunnen echt luisteren naar al hun medewerkers. Gemeenschappen kunnen consensus vinden, zelfs in complexiteit.
Source Available: Samen Het Gemeengoed Bouwen
We geloven dat hulpmiddelen voor democratische participatie gemeenschappelijke middelen zouden moeten zijn die alle gemeenschappen verheffen. Daarom zijn al onze verbeteringen aan de open-source bibliotheken ook open source. Wanneer wij een probleem oplossen - zoals het behoud van grafiekconsistentie tijdens updates of het omgaan met code-switching in meertalige gemeenschappen - profiteert iedereen. En wanneer anderen deze tools verbeteren, wordt ons platform ook beter. Het is een deugdzame cyclus die sneller beweegt dan welk bedrijf alleen kon.
Dank U, Arindam
Nu Arindam zijn volgende avontuur met agentische grafieken begint, zijn we dankbaar voor de basis die hij heeft helpen bouwen. Zijn werk belichaamt wat we waarderen bij Dembrane: technische uitmuntendheid in dienst van menselijke verbinden, open samenwerking boven eigen voordeel, en het geduld om moeilijke problemen goed op te lossen.
De uitdagingen die hij aanging zijn het onopvallende maar essentiële werk van het maken van AI die gemeenschappen dient in plaats van andersom.
We kijken ernaar uit om te zien waar Arindams reis verder naartoe leidt. De deur blijft open voor toekomstige samenwerking, vooral als we werken om meer van zijn krachtige innovaties in productie te brengen.
Bij Dembrane geloven we dat mensen het weten. Onze tools helpen hen eenvoudigweg om die kennis te delen. Leer meer over onze missie op dembrane.com.